The stack we picked — Bun, Hono, Drizzle, TanStack Start
Aleksey Svetlitskiy
May 14, 2026 · 12 min read

We rewrote the FluxNow dashboard once. Not because the product changed — because the framework was making us work for it.
Next.js had been our default since the dashboard's first commit. By month nine, the production build was creeping past eight minutes on CI and four on a developer laptop. The bundle was twice what an admin panel had any business shipping. App Router was a smart design we didn't need. None of it was broken — all of it was friction we were paying for, every push, every preview, every PR.
One weekend we replaced Next.js with TanStack Start. CI builds dropped to under a minute. The bundle halved. Nothing about the product changed. That night turned out to be the closest thing we have to a founding story for the FluxNow dashboard stack. But the fight wasn't really about Next.js. It was about a question every team eventually has to answer: how much of your future are you willing to rent?
One rule, five priorities
We were optimising for five things, in priority order:
- Portable across providers.
- Runs on bare metal we own.
- Agent-friendly, typed APIs.
- End-to-end type safety.
- No proprietary deploy magic anywhere in the critical path.
Every layer had to pass one test: can we move off it in a weekend?
If a swap meant rewriting half the app, the dependency was wrong. Everything below is that rule, applied once per layer.
The stack at a glance
For the skimmers:
- Bun — runtime and package manager
- Hono — HTTP layer on Web Fetch standards
- Drizzle ORM — SQL-first, no codegen, no native binary
- TanStack Start — dashboard framework, file-based router on Vite
- oRPC — typed client/server calls without a separate gateway
- Better Auth — a library that owns nothing
- BullMQ — background jobs on Redis
- PGlite — Postgres in WebAssembly, for local dev
The whole thing builds end-to-end in under a minute, runs on Bun in a Docker image under 100 MB, and is replaceable in pieces. Read on for why each choice.
Bun, over Node + pnpm
Bun is our package manager and our runtime. Faster install than pnpm. TypeScript and JSX run with no build step. We bundle the API with bun build for a small distroless image — the --compile single-binary build is the next move.
We accepted a smaller ecosystem and a couple of npm packages with rough edges under Bun's Node compat — two hits in eighteen months. Every Bun-only surface lives in scripts and entrypoints, never deep in business logic, so moving back to Node 22 is one line in the Dockerfile and one line in CI. We've proved it: when Bun's stack traces weren't helping, we ran the same code under Node in a debugger and shipped from there. Deno was the other TS-native runtime we considered — Web Standards-first, but the npm-compat story is shakier than Bun's.
Hono, over Express, Fastify, Nest
Hono is our HTTP layer. It's built on the Web Fetch API — Request in, Response out — which means the same router runs unchanged on Bun, Node, Cloudflare Workers, Deno, and AWS Lambda. The bundle is small. There is no middleware soup to debug.
Less batteries-included than Nest — we supply auth, validation, RPC from libraries that do one thing each, and we have never regretted it. Reading any handler in the codebase tells you exactly what the request will do, top to bottom. Express loses from the other direction: every interesting feature (streams, async middleware, typed routes) is a third-party shim on top of a 2011 mental model. Elysia is the Bun-native peer that's faster in pure-Bun benchmarks, but Bun-locked — that violates the portability rule.
Drizzle, over Prisma, Kysely
Drizzle is the ORM. It's SQL-first: queries compile to the SQL you'd have written by hand, with full type inference from the schema. There is no codegen step in CI. No native binary. No prisma engine to wedge a deploy.
The big one: Drizzle runs in any TypeScript environment with a Postgres driver, including @electric-sql/pglite — Postgres compiled to WebAssembly. Every dev gets a real Postgres-compatible database on their laptop with zero containers; tests run against PGlite under Vitest, local dev defaults to PGlite, and the first time someone needs a real Postgres they set DATABASE_URL and everything keeps working.
That's the entire local-vs-prod database story. No Docker Compose. No make db. No "did you forget to start the seed script."
Drizzle's migration tooling is lighter than Prisma's; we supplement it with a small in-repo idempotency linter so every migration is safe to run twice (preview-database life means they often are). We passed on Prisma because codegen plus a separate schema language plus a Rust binary is exactly the lock-in we were trying to avoid, and we did not want to ship a database engine in our Docker image. TypeORM is still big in TS land, but the decorator + repository sprawl is exactly the runtime-metadata API surface we wanted to escape.
TanStack Start, over Next.js
We ran Next.js for nine months. App Router is a genuinely smart design, but builds got slower with every feature, the deploy primitives leaned us towards Vercel-shaped infrastructure we don't run on, and server components were a tax we were paying for an admin panel that didn't need them. We were optimising for a framework, not a product.
The night we rewrote on TanStack Start, three things became immediately obvious:
- The file-based router is just a router. It does not own your build. The bundle is whatever your Vite config says.
- Loaders are loaders. They are functions. They run where you tell them to.
- The whole framework is small enough to read in an afternoon. We have. Twice.
The build is back to finishing in seconds. The production bundle is a Bun binary plus static assets. The rewrite shell took a weekend; the long tail of route-loader and data-fetch ports landed over the following two weeks.
The tradeoff is ecosystem size: fewer Stack Overflow answers, fewer plugins, no "just deploy to Vercel" button. We trade that for a stack we fully understand. Staying with Next would have meant deploy primitives that lean towards Vercel, and we don't deploy to Vercel.
On the rest of the UI layer: Tailwind v4 for styling, a hand-rolled FluxNow Design System for primitives, TanStack Query for server state, and deliberately no client-state library. The design-system layer is its own retrospective — next post.
Better Auth, over Clerk, Auth0, NextAuth
Auth is the layer where vendor lock-in hurts most. We use Better Auth precisely because it is a library that owns nothing: no per-MAU pricing, no hosted database, no proprietary session format. Sessions live in our Postgres — DB-backed, not JWT. We back it onto Zitadel Cloud as the upstream IdP and could move that any time.
That's the entire auth integration. The session middleware reads cookies, the route handler delegates to the library. We can swap libraries tomorrow.
We passed on Clerk: the moment we wanted SSO or custom domains the bill jumps to the Pro tier, and the pricing axis only goes up from there. Clerk is genuinely well-built — we are anti-pricing-tied-to-features-that-should-be-table-stakes for a B2B product.
BullMQ, not Inngest
We ship BullMQ on top of Redis in the dashboard, with our own retry and stage logic for the multi-step bits. Scoping caveat worth saying out loud: other parts of the FluxNow stack — notably the agent-orchestration pipeline — do run on Inngest, where checkpoint-resume durable execution earns its keep. The dashboard's job profile (short jobs, cron, fan-out) does not need that, and we did not want a hosted service in this surface's deploy critical path.
BullMQ gives us a job queue we understand, a Redis we already operate, and zero new vendors. Add bullmq-otel for distributed tracing across producers and workers, and you have most of what "hosted job runners" sell, minus the runner. What it doesn't give us: durable-by-default workflows that survive a worker restart mid-step. We pay for that by writing the persistence ourselves, in Postgres, for the workflows that need it.
If the persistence layer ever outgrows what we can maintain in-repo, we'll revisit Inngest or Trigger.dev — both are now self-hostable enough to pass the vendor test. We have a small spike booked for Q3.
What we explicitly left out
- No GraphQL. We use oRPC for typed client–server calls. End-to-end types come from the schema, not a separate gateway. The killer feature for us is auto-generated OpenAPI from the same procedure definitions our typed client uses — one source of truth, zero duplicated schemas. It also means LLMs and agentic clients can call our API against the spec we already publish, no bespoke tool descriptions required. tRPC is a fine pick; we picked oRPC because we wanted OpenAPI without writing it twice.
- No tRPC. Same shape, slightly more weight, slightly more framework opinion. oRPC won on diff size.
- No Vercel SDK, no
@vercel/*anything. Every place a@vercel/*import would have appeared, we use the underlying standard. The Vercel AI SDK is the one exception — a thin model adapter, not a hosting concern — and we'd swap even that the moment it tries to grow. - No proprietary deploy primitives. Every environment, including local laptops, builds the same Docker image and runs the same
start.ts.
A composability flex
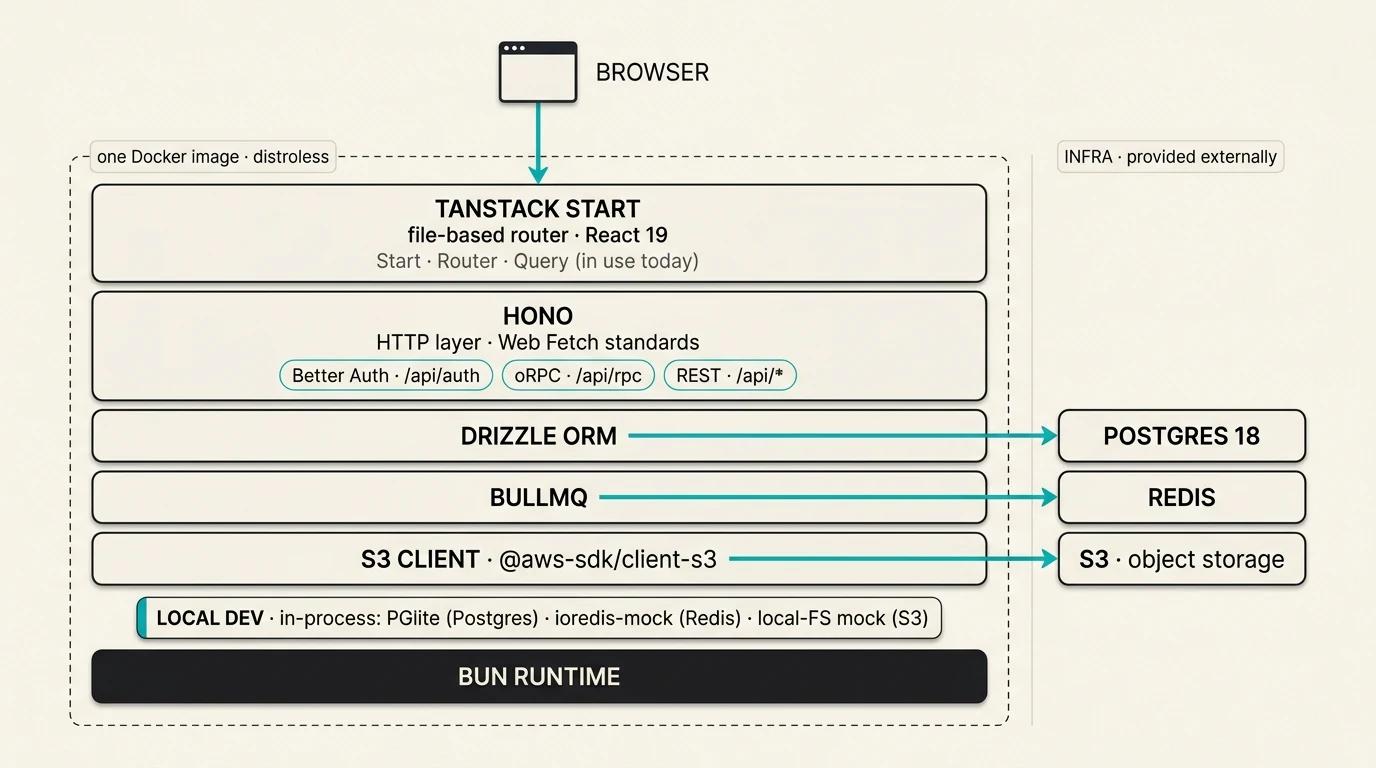
The dashboard's HTTP entry point is a single file under 100 lines. One Hono app mounts three lanes side by side: /api/auth/* delegates to Better Auth, /api/rpc/* to the oRPC router, and the handful of REST routes that need a stable public contract sit alongside both. Drizzle queries live in the route handlers; nothing wraps the wiring. Hono is plumbing, not a runtime.
What we'd consider adding
The stack isn't finished, just stable. The candidates currently on our "try once we have a Friday" list:
- OpenTelemetry to replace our hand-rolled Prometheus exporters in the dashboard. The engine already emits OTLP; we want one tracing model end-to-end.
- Effect for the corner of the codebase chained too deep in
try/catch. Typed errors as data, not exceptions. We aren't going to rewrite the world — Effect-or-nothing zealotry is its own anti-pattern — but a few hot paths would read better. - Trigger.dev v4 as the BullMQ alternative if our durable-workflow needs grow. Now fully self-hostable, which means it passes the vendor test.
- PostHog server-side in dash itself (we already use it in the marketing site) so we stop running two analytics models.
- More Postgres 18 features we haven't pulled in yet — async I/O, native
uuidv7(), logical replication from a standby — to drop workarounds we wrote in 2024. - TanStack Table + shadcn primitives (Base UI flavor). Natural next bets for the data-grid surfaces and the primitive layer (Dialog, Combobox, DatePicker, etc.) — same library-family rationale as Query and Router for Table; shadcn's
--base-uiflag means the primitive layer doesn't depend on Radix's slowing release cadence. The FluxNow DS visual layer stays ours.
Notice what isn't on that list: a new frontend framework, a new ORM, a new auth library. We're done with that kind of churn — the closest near-term experiment is TanStack DB, which adds reactive joins on top of Query. Same library family, same design philosophy.
The replaceability test
The dashboard runs on Bun in a single Docker image, fits comfortably under 100 MB, and rebuilds end-to-end in well under a minute. Every layer in it can be swapped in a weekend without rewriting the others:
- Bun → Node — change the Dockerfile base image and one line in CI.
- Hono → Fastify — rewrite the four route registrations in
api-app.ts. - Drizzle → Kysely — rewrite the queries, keep the schema.
- TanStack Start → Remix — change
src/routes/*.tsximport shapes. - Better Auth → anything OIDC-compliant — replace the handler, keep the Zitadel.
- BullMQ → Trigger.dev — replace the queue wrappers in
src/lib/jobs/*.
None of those swaps is easy. None of them is trapped. That is the test.
What we'd flag to a reviewer
Anti-cargo-cult is a discipline. The honest inventory of things a senior reviewer would (rightly) push back on:
- TanStack Table v8 in production, v9 still alpha. When v9 lands the migration will not be a no-op. We are not on the bleeding edge of that library and we are not pretending to be.
- Better Auth's OIDC Provider plugin is documented as not production-ready. We don't host an IdP downstream — Zitadel does — so this doesn't bite us. If you do, it would.
- BullMQ has no checkpoint-resume durable execution. A workflow that crashes at minute 28 of a 30-minute step re-runs the step. For our jobs (short, cron, fan-out) this is a non-issue. For an LLM-orchestration workflow it would be a dealbreaker — say so out loud when picking.
- Hono RPC's type-instantiation cost scales with route count. The mitigation is splitting routes into sub-apps with their own
typeofexports, which we do from day one. Skip that and the TypeScript server gets painful around 200 routes. - Drizzle's relational planner can emit non-optimal SQL on deeply nested includes. For hot-path queries we drop to
db.execute(sql`...`)and write the CTE by hand. The escape hatch exists; you have to remember to use it. - TanStack itself is a concentrated bet. Start, Router, Query — soon DB and Form too. We have traded Vercel-shape lock-in for TanStack-shape lock-in, and we know it. We think it is the better trade (one team, one design philosophy, smaller blast radius if any single library stalls), but the honest framing is that we picked which lock-in to accept rather than escaping lock-in entirely.
Knowing all of that, we still ship the stack. The replaceability rule means we can change our mind on any one of these without rewriting the others. That is the whole point.
The rest is implementation detail, and we are going to keep writing about it here.
— Aleksey Svetlitskiy, Principal Engineer / Engineering Partner, FluxNow
Related posts